Administration Guides
Vérifier le bon fonctionnement
Noeuds du cluster
Pour vérifier l'état du service sur les noeuds :
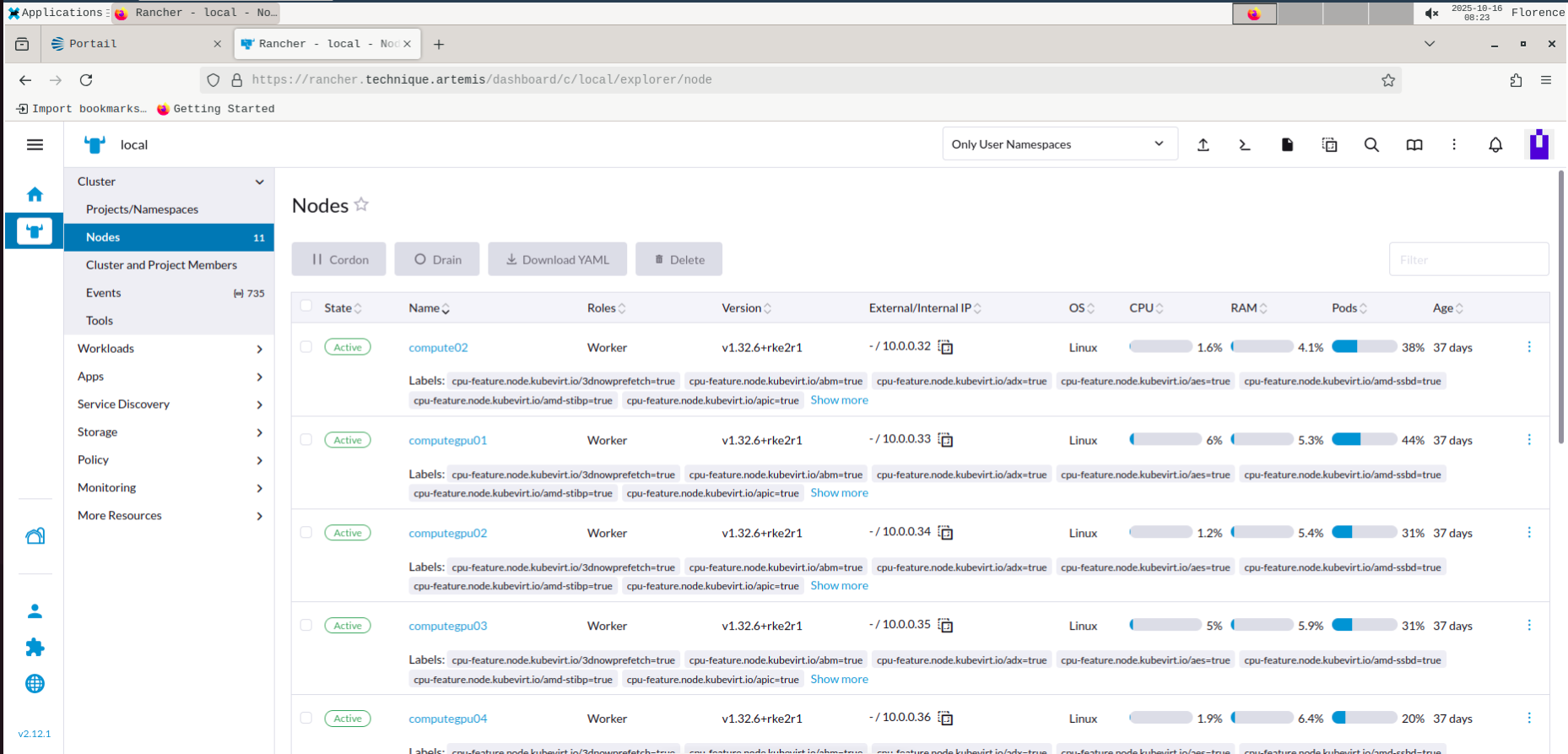
Le Status doit être Ready
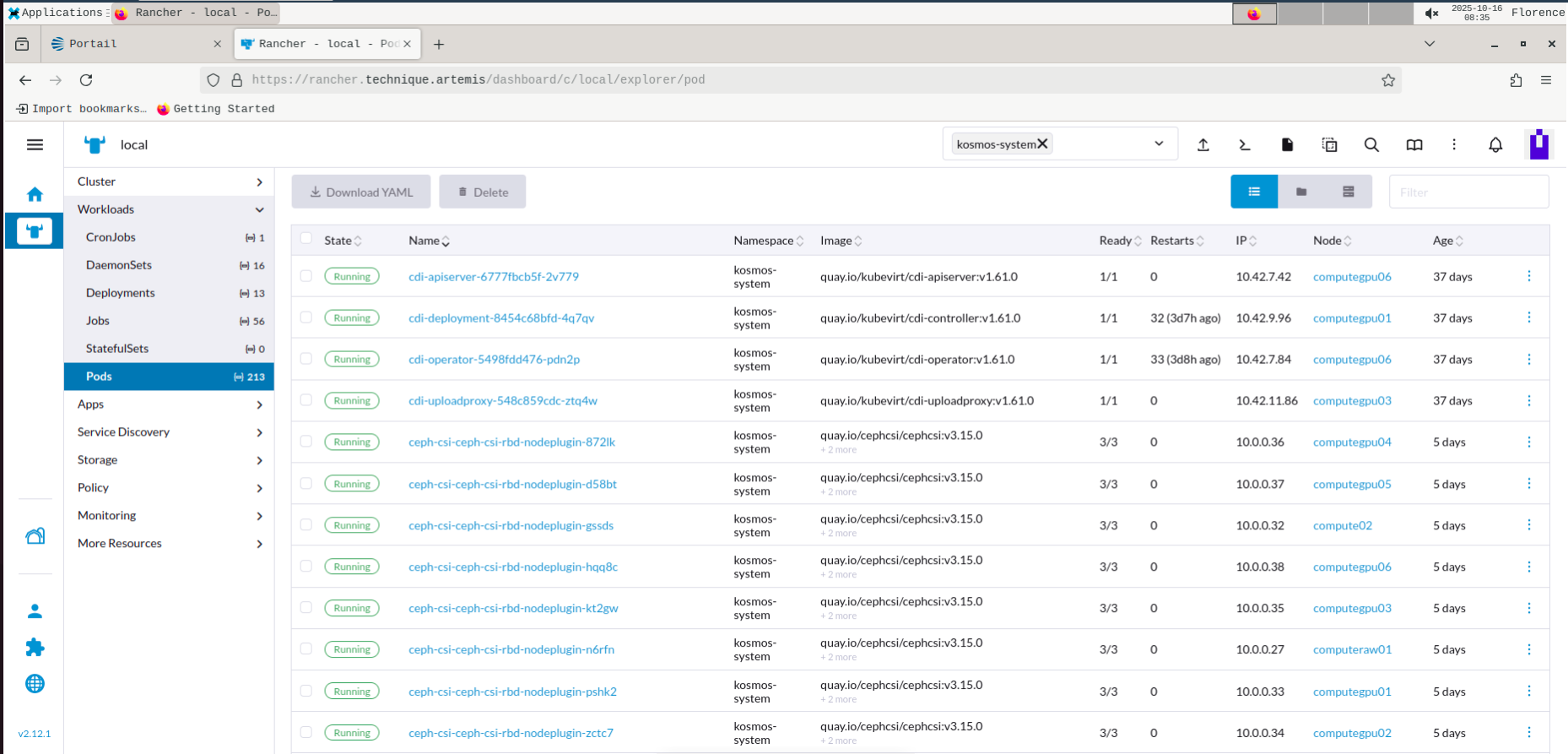
Pods des services
L'ensemble des pods présent dans ce namespace kosmos-system doivent avoir le STATUS à 1/1 Running ou 0/1 Completed.
kubelet
Le kubelet est déployé via le process rke2-server sur les masters et le process rke2-agent sur les workers.
On se connecte sur la VM du noeud kubernetes que l'on souhaite vérifier pour connaitre l'état du service (*-server ou *-agent) :
systemctl status rke2-server
● rke2-server.service - Rancher Kubernetes Engine v2 (server)
Loaded: loaded (/usr/local/lib/systemd/system/rke2-server.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2023-04-19 09:39:14 UTC; 5h 51min ago
Docs: https://github.com/rancher/rke2#readme
Process: 1498 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS)
Process: 1436 ExecStartPre=/sbin/modprobe br_netfilter (code=exited, status=0/SUCCESS)
Process: 1415 ExecStartPre=/bin/sh -xc ! /usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service (code=exited, status=0/SUCCESS)
Main PID: 1600
Tasks: 138
Memory: 877.6M
CGroup: /system.slice/rke2-server.service
├─1600 /usr/local/bin/rke2 server
├─1991 containerd -c /var/lib/rancher/rke2/agent/etc/containerd/config.toml -a /run/k3s/containerd/containerd.sock --state /run/k3s/containerd --root /var/lib/rancher/rke2/agent/containerd
├─2007 kubelet --volume-plugin-dir=/var/lib/kubelet/volumeplugins --file-check-frequency=5s --sync-frequency=30s --address=0.0.0.0 --alsologtostderr=false --anonymous-auth=false --authenticat>
├─2110 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id 5438043a74ed89f3444ecc4ceb41cbeda6e91360ec61b081d58d3df9d8c0cf95 -address /run>
├─2134 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id 436c7deb37f0360a8c1fce351d825a1db7ac7448c16f0d4df95fab746ce74a64 -address /run>
├─2135 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id 7f7830ba6bf7c9100e23babf6106fcc09c11be091191bda928290bb5f1a034e4 -address /run>
├─2156 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id ab4d36b436650ef8cafe2046be73547b28c3d5788da77c58c4be251052b7d4eb -address /run>
├─2498 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id 33a4993a380c956342f613ea0066d83deb83cb5c8fa7f9669c82254ed5a2bff5 -address /run>
├─2525 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id e7625a367a5b9815867be68ba783acc8bcfe5cfa85f3ddcc97a46f71de8db0cf -address /run>
└─3548 /var/lib/rancher/rke2/services_donnees/v1.23.12-rke2r1-ea17978f3f8a/bin/containerd-shim-runc-v2 -namespace k8s.io -id 9430f96da6432ae66fbb42c94e6d1d18787d20a8f8bcb12efb04f3bfbbc20ae6 -address /run>
Le service doit être active (running)
Vérification des autres services Kubernetes
Les autres services kubernetes sont le réseau (cilium), le dns interne (coredns), les ingress (nginx-ingress), les provisioneurs de volume (ceph-csi), les "cluster policies" (gatekeeper), le gpu (nvidia).
Vérifier avec la commande suivante, que l'ensemble des contrats de déploiement est respecté :
for ns in $(kubectl get namespace --no-headers -o custom-columns=NS:.metadata.name | grep "\-sys\|\-ingress"); do kubectl get deploy,sts,ds -n $ns; done
Exemple d'exécution :
No resources found in cattle-fleet-clusters-system namespace.
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/fleet-agent 1/1 1 1 9d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/fleet-controller 1/1 1 1 41d
deployment.apps/helmops 1/1 1 1 41d
No resources found in cattle-impersonation-system namespace.
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/capi-controller-manager 1/1 1 1 41d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/rancher 3/3 3 3 41d
deployment.apps/rancher-webhook 1/1 1 1 41d
deployment.apps/system-upgrade-controller 1/1 1 1 41d
No resources found in cattle-ui-plugin-system namespace.
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cdi-apiserver 1/1 1 1 41d
deployment.apps/cdi-deployment 1/1 1 1 41d
deployment.apps/cdi-operator 1/1 1 1 41d
deployment.apps/cdi-uploadproxy 1/1 1 1 41d
deployment.apps/ceph-csi-ceph-csi-rbd-provisioner 3/3 3 3 9d
deployment.apps/gpu-operator 1/1 1 1 41d
deployment.apps/gpu-operator-node-feature-discovery-gc 1/1 1 1 41d
deployment.apps/gpu-operator-node-feature-discovery-master 1/1 1 1 41d
deployment.apps/kube-vip-cloud-provider 1/1 1 1 42d
deployment.apps/topolvm-controller 2/2 2 2 42d
deployment.apps/virt-api 2/2 2 2 41d
deployment.apps/virt-controller 2/2 2 2 41d
deployment.apps/virt-operator 1/1 1 1 41d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/ceph-csi-ceph-csi-rbd-nodeplugin 11 11 11 11 11 <none> 9d
daemonset.apps/falco 14 14 14 14 14 <none> 33d
daemonset.apps/gpu-feature-discovery 6 6 6 6 6 nvidia.com/gpu.deploy.gpu-feature-discovery=true 41d
daemonset.apps/gpu-operator-node-feature-discovery-worker 14 14 14 14 14 <none> 41d
daemonset.apps/kube-vip 14 14 14 14 14 <none> 41d
daemonset.apps/monitoring-stack-prometheus-node-exporter 14 14 14 14 14 kubernetes.io/os=linux 39d
daemonset.apps/nvidia-container-toolkit-daemonset 6 6 6 6 6 nvidia.com/gpu.deploy.container-toolkit=true 41d
daemonset.apps/nvidia-dcgm-exporter 6 6 6 6 6 nvidia.com/gpu.deploy.dcgm-exporter=true 41d
daemonset.apps/nvidia-device-plugin-daemonset 6 6 6 6 6 nvidia.com/gpu.deploy.device-plugin=true 41d
daemonset.apps/nvidia-device-plugin-mps-control-daemon 0 0 0 0 0 nvidia.com/gpu.deploy.device-plugin=true,nvidia.com/mps.capable=true 41d
daemonset.apps/nvidia-driver-daemonset-6.8.0-62-generic-ubuntu24.04 6 6 6 0 6 feature.node.kubernetes.io/kernel-version.full=6.8.0-62-generic,nvidia.com/gpu.deploy.driver=true 41d
daemonset.apps/nvidia-mig-manager 0 0 0 0 0 nvidia.com/gpu.deploy.mig-manager=true 41d
daemonset.apps/nvidia-operator-validator 6 6 6 6 6 nvidia.com/gpu.deploy.operator-validator=true 41d
daemonset.apps/topolvm-lvmd-0 11 11 11 11 11 <none> 42d
daemonset.apps/topolvm-node 11 11 11 11 11 <none> 42d
daemonset.apps/virt-handler 11 11 11 11 11 kubernetes.io/os=linux 41d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/argo-cd-argocd-applicationset-controller 1/1 1 1 41d
deployment.apps/argo-cd-argocd-notifications-controller 1/1 1 1 41d
deployment.apps/argo-cd-argocd-redis 1/1 1 1 41d
deployment.apps/argo-cd-argocd-repo-server 1/1 1 1 41d
deployment.apps/argo-cd-argocd-server 1/1 1 1 41d
deployment.apps/cert-manager 1/1 1 1 30d
deployment.apps/cert-manager-cainjector 1/1 1 1 30d
deployment.apps/cert-manager-webhook 1/1 1 1 30d
deployment.apps/clickhouse-operator-altinity-clickhouse-operator 1/1 1 1 42d
deployment.apps/eds-back-kosmos-eds-api-server 1/1 1 1 41d
deployment.apps/eds-back-kosmos-eds-webhook 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-ch 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-kafka 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-opensearch 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-pg 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-s3 1/1 1 1 41d
deployment.apps/eds-back-kosmos-mds-vs 1/1 1 1 41d
deployment.apps/eds-front-kosmos-eds-ui 1/1 1 1 41d
deployment.apps/eds-front-oauth2-proxy 1/1 1 1 41d
deployment.apps/iad-os-shared 1/1 1 1 41d
deployment.apps/iad-pg-shared 1/1 1 1 41d
deployment.apps/iad-s3-shared 1/1 1 1 41d
deployment.apps/kosmos-cli 1/1 1 1 41d
deployment.apps/portal-back-kosmos-portal-api 1/1 1 1 41d
deployment.apps/portal-back-kosmos-proximg 1/1 1 1 41d
deployment.apps/portal-front-kosmos-kosmos-portal-ui 1/1 1 1 41d
deployment.apps/portal-front-kosmos-oauth2-proxy 1/1 1 1 41d
deployment.apps/sap-back-kosmos-api-server 1/1 1 1 41d
deployment.apps/sap-back-kosmos-controller 1/1 1 1 41d
deployment.apps/sap-back-kosmos-decorator 1/1 1 1 41d
deployment.apps/sap-back-kosmos-logs-server 1/1 1 1 41d
deployment.apps/sap-back-kosmos-plugin-datahub 1/1 1 1 41d
deployment.apps/sap-back-kosmos-plugin-envmanager 1/1 1 1 41d
deployment.apps/sap-back-kosmos-plugin-exposure 1/1 1 1 41d
deployment.apps/sap-back-kosmos-plugin-manager 1/1 1 1 41d
deployment.apps/sap-back-kosmos-plugin-pvmanager 1/1 1 1 41d
deployment.apps/sap-front-kosmos-sap-ui 1/1 1 1 41d
deployment.apps/sap-front-oauth2-proxy 1/1 1 1 41d
NAME READY AGE
statefulset.apps/argo-cd-argocd-application-controller 1/1 41d
statefulset.apps/sap-back-kosmos-api-worker 3/3 41d
No resources found in kosmos-vm-systran namespace.
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cilium-operator 2/2 2 2 42d
deployment.apps/rke2-coredns-rke2-coredns 3/3 3 3 42d
deployment.apps/rke2-coredns-rke2-coredns-autoscaler 1/1 1 1 42d
deployment.apps/rke2-metrics-server 1/1 1 1 42d
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/cilium 14 14 14 14 14 kubernetes.io/os=linux 42d
daemonset.apps/rke2-ingress-nginx-controller 14 14 14 14 14 kubernetes.io/os=linux 42d
On voit que tous les "DESIRED" sont égaux aux "CURRENT" pour les "daemonset" ou que les "READY" X/X sont bien respectés pour les "deployment" et les "statefulset".
Interface de supervision pour Kubernetes
Aller dans le portail admin et vérifier la supervision des services kubernetes via Grafana.
Ou bien en se connectant via la console d'administration de kubernetes aussi disponible via le portail amdin si la supervision n'est pas disponible.
Le "control plane"
Vérifier l'état du "control plane".
kubectl cluster-info
kubectl cluster-info dump #Pour avoir beaucoup plus d'information.
Exemple de résultat :
Kubernetes control plane is running at https://kubernetes.technique.artemis:6443
CoreDNS is running at https://kubernetes.technique.artemis:6443/api/v1/namespaces/kube-system/services/rke2-coredns-rke2-coredns:udp-53/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Vérifier la persistance kubernetes
kubectl exec -it pod/etcd-kubm-k8s00-master-1 -n kube-system -- /bin/sh
sh-4.4$ ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cacert /var/lib/rancher/rke2/server/tls/etcd/server-ca.crt --cert /var/lib/rancher/rke2/server/tls/etcd/server-client.crt --key /var/lib/rancher/rke2/server/tls/etcd/server-client.key -w table --cluster=true endpoint health
sh-4.4$ ETCDCTL_API=3 etcdctl --endpoints 127.0.0.1:2379 --cacert /var/lib/rancher/rke2/server/tls/etcd/server-ca.crt --cert /var/lib/rancher/rke2/server/tls/etcd/server-client.crt --key /var/lib/rancher/rke2/server/tls/etcd/server-client.key -w table --cluster=true endpoint status
Exemple d'affichage pour la partie HEALTH
+--------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+--------------------------+--------+-------------+-------+
| https://10.10.3.155:2379 | true | 15.540412ms | |
| https://10.10.3.83:2379 | true | 18.54766ms | |
| https://10.10.3.57:2379 | true | 19.070306ms | |
| https://10.10.3.131:2379 | true | 19.427417ms | |
| https://10.10.3.80:2379 | true | 27.754429ms | |
+--------------------------+--------+-------------+-------+
Exemple d'affichage pour la partie STATUS
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://10.10.3.131:2379 | fe2e72216a2223d | 3.4.13 | 139 MB | false | false | 3651 | 32726291 | 32726291 | |
| https://10.10.3.83:2379 | 35e6882c2b680ad9 | 3.4.13 | 139 MB | false | false | 3651 | 32726291 | 32726291 | |
| https://10.10.3.80:2379 | adda4e8100b99844 | 3.4.13 | 139 MB | false | false | 3651 | 32726291 | 32726291 | |
| https://10.10.3.155:2379 | e19dec06160eae9a | 3.4.13 | 139 MB | false | false | 3651 | 32726291 | 32726291 | |
| https://10.10.3.57:2379 | e729ae6437426769 | 3.4.13 | 139 MB | true | false | 3651 | 32726291 | 32726291 | |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
Vérifier les ingress
Au-delà de l'état "Running" des pods, vous pouvez utiliser les commandes suivantes :
# Description de l'ingress, vérification des évènements
kubectl describe ingress <ingress-resource-name> -n <namespace-of-ingress-resource>
# Vérification des logs des contrôleurs
kubectl logs -n <namespace> nginx-ingress-controller-xxxxx-yyyy
# Extraction de la configuration
kubectl exec -it -n <namespace-of-ingress-controller> nginx-ingress-controller-67956bf89d-fv58j -- cat /etc/nginx/nginx.conf
Les namespaces des contrôleurs d'ingress sont:
- kube-system
Page de référence: https://kubernetes.github.io/ingress-nginx/troubleshooting/
Arrêter le service K8S
Stopper les applications métiers
Demander à l'Administrateur applications l'arrêt des applications.
Stopper le cluster kube
Arrêter tout d'abord tous les pods des workers avec les commandes suivantes :
kubectl cordon --all
kubectl get nodes | grep Ready | grep -v master | cut -d' ' -f 1 | xargs kubectl drain --delete-emptydir-data --ignore-daemonsets --force=true --disable-eviction
Arrêter ensuite tous les pods des masters avec la commande suivante :
kubectl get nodes | grep Ready | grep master | cut -d' ' -f 1 | xargs kubectl drain --delete-emptydir-data --ignore-daemonsets --force=true --disable-eviction
Vous pouvez ensuite arrêter les VMs master de kube.
Démarrer le service K8S
Redémarrer les VMs master et VMs (ou serveur) Worker Kubernetes et attendre qu'elles redémarrent.
Vérifier que les noeuds sont bien présents :
kubectl get nodes
Exécuter la commande suivante pour que les noeuds acceptent des nouveaux pods :
kubectl get nodes | grep Ready | cut -d' ' -f 1 | xargs kubectl uncordon
Et si l'on souhaite préciser le noeud k8s, il faut lancer la commande suivante :
kubectl uncordon nomdunoeud
Démarrer/Arrêter un service
Les pods sont automatiquement démarrés après leur déploiement (installation).
Ils peuvent néanmoins être arrêtés par la commande kubectl scale et relancer par la même commande (en changeant le nombre de replicas).
Le nombre de replicas dimensionne le nombre de pods qui seront déployés pour ce service.
Exemple avec le service Keycloak
replicas=$(kubectl -n kosmos-iam get sts keycloak-cluster -o jsonpath='{.spec.replicas}' )
kubectl -n kosmos-iam scale sts keycloak-cluster --replicas=0
kubectl -n kosmos-iam scale sts keycloak-cluster --replicas=${replicas}
Redémarrer un service
Pour redémarrer un service sans interruption de service le système de rollout restart de k8s peut être utilisé
kubectl -n kosmos-iam rollout restart sts keycloak-cluster
ou on peut supprimer le pod ciblé (suivant le cas de figure) qui sera relancé automatiquement :
kubectl -n kosmos-iam delete pod keycloak-cluster-0
Augmenter/Diminuer les ressources
les replicas
En ligne de commande
Par exemple, pour passer le nombre de réplicas (pods) de 2 à 3 sur le service Keycloak
kubectl -n kosmos-iam scale sts keycloak-cluster --replicas=3
Modification via la console
- Depuis le portal d'administration, acceder au portail Rancher.
- Sélectionner le
Deploymentsou leStatefulSetsde l'application cible - Dans le champ recherche sélectionner le namespace du moyen de stockage dont vous souhaitez modifier le nombre de replica
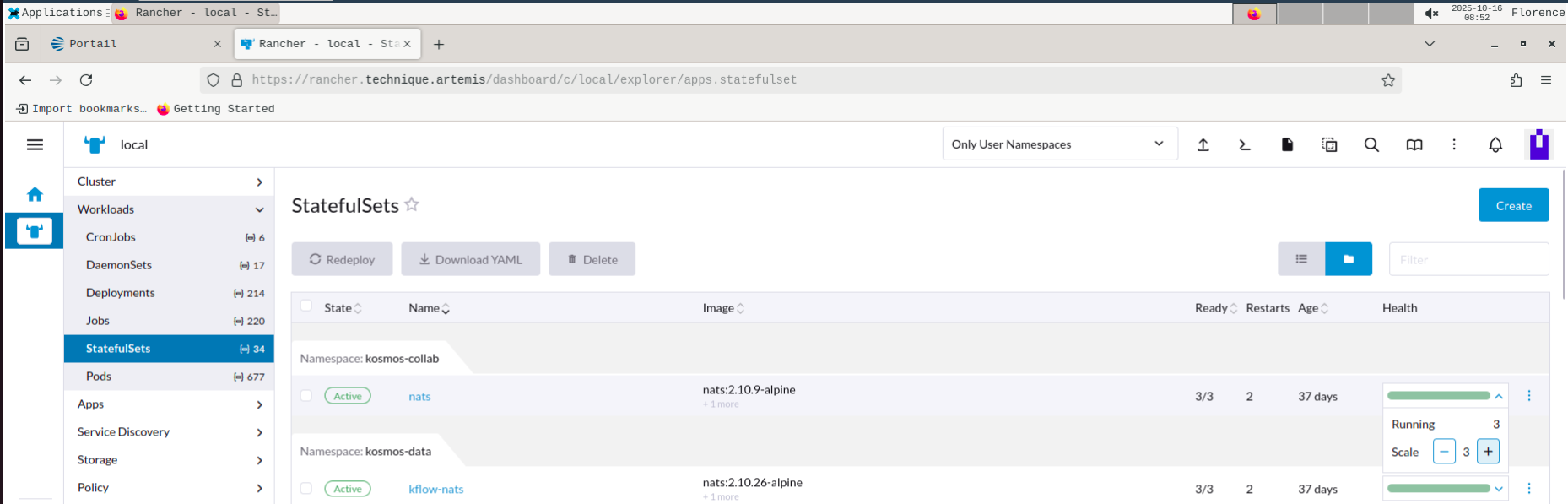
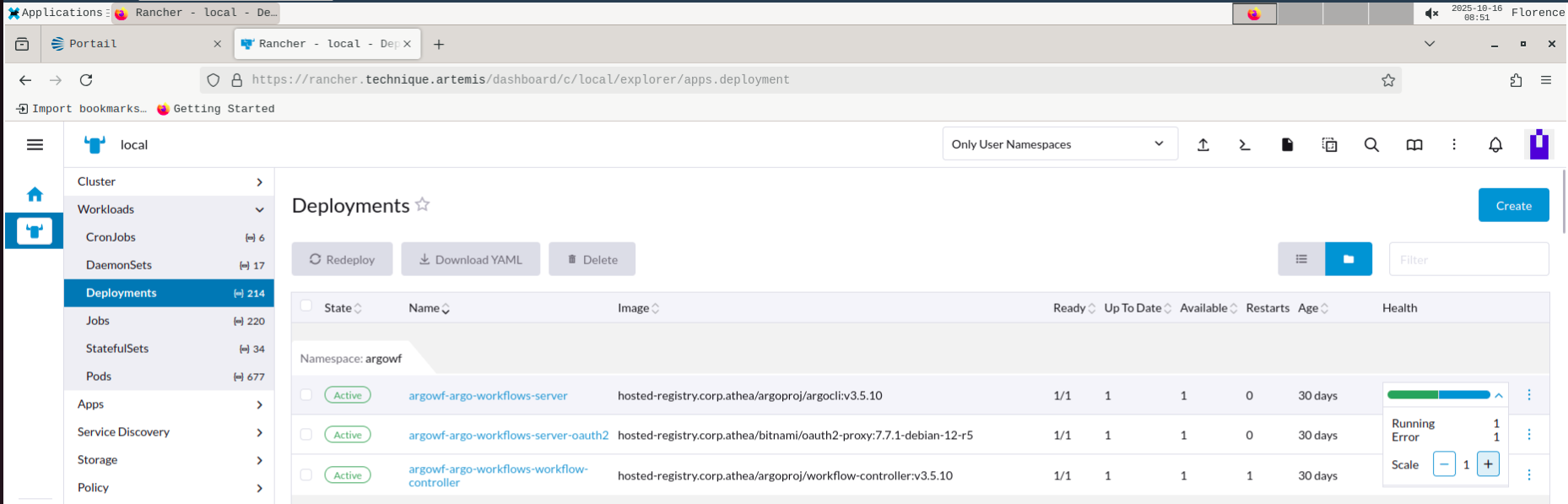
- Choisir le nombre de replica attendus à la hausse ou à la baisse suivant le besoin
Les ressources RAM/CPU allouée
En ligne de commande
Pour modifier les ressources de type RAM/CPU il faut éditer le manifest du workload (suivant le composant: sts, deploy ou rs) pour remplacer les valeurs des request/limit du contenneur souhaité
Par exemple, pour augmenter les ressources du container keycloak de tous les pods Keycloak:
kubectl -n kosmos-iam edit sts keycloak-cluster
resources:
limits:
cpu: "2"
memory: 1536Mi
requests:
cpu: 250m
memory: 512Mi
Ce type de modification est réalisable à chaud mais n'est pas persisté. En effet, une reinstallation du service ou un rollover du déploiement reviendra au paramétrage livré.
Passer un worker en mode maintenance
Pour passer un worker en mode maintenance, il faut tout d'abord l'exclure du scheduler de Kubernetes (cordon) puis le vider de ses conteneurs (les pods se réinstancieront sur les autres noeuds). La commande drain réalise les deux actions:
kubectl drain --delete-emptydir-data --ignore-daemonsets --force=true --disable-eviction <nom d'une vm worker>
--delete-emptydir-datapermet de supprimer des pods qui utilisent des répertoires vides (les données locales seront supprimées lorsque le noeud est drainé).--ignore-daemonsets=truepermet d'ignorer les DaemonSets--forcepermet de supprimer les pods non managés par un Deployment--disable-evictionpermet de forcer le drain à utiliser la suppression, même si l'expulsion est prise en charge. Cela contournera la vérification PodDisruptionBudgets.
Une fois cette action effectuée, le worker peut subir n'importe quelle opération de maintenance.
Spécificité topolvm
Apres le drain du noeud, les POD initialement présents sur ce noeud possédant des PVC (Volumes) sont en Pending car leurs PVC sont toujours attachés au noeud initial. Il convient alors de réaliser les actions suivantes pour déplacer les volumes des pods:
- supprimer le PVC afin qu'un autre PVC s'instancie automatiquement sur le nouveau noeud, créant un nouveau PV (volume) sur ce noeud.
- arrêter le pod pour "démonter" le volume cible et permettre la copie des données
- montage, copie des données, démontage
- relance du pod.
Le script /data/apps/platform-provisioner/scripts/pvc-recovery.sh génère l'ensemble des commandes pour réaliser ces actions pour un namespace et un pod donnés.
Usage:
cd /data/apps/platform-provisioner/scripts
./pvc-recovery.sh -n <namespace> -p <pod>
Les commandes générées sont réparties dans 3 scripts à exécuter dans l'ordre:
- /data/pvc-recovery/pvc-recovery-<namespace>-<pod>/part1.sh
- /data/pvc-recovery/pvc-recovery-<namespace>-<pod>/part2.sh
- /data/pvc-recovery/pvc-recovery-<namespace>-<pod>/part3.sh
Information importante : la storageClass lvm-provisioner doit obligatoirement être en reclaimPolicy: Retain (et non Delete) afin que le PV d'origine ne soit pas supprimé et reste accessible pour la copie des données.
Sortir un worker du mode maintenance
Il suffit pour cela de replacer le worker dans le scheduling de Kubernetes
kubectl uncordon <nom d'une vm worker>
node/<nom d'une vm worker> uncordoned
Passer un master en mode maintenance
L'opération est la même que pour un worker.
Néanmoins, si vous souhaitez éteindre un master une fois passé en maintenance, il faut faire attention au nombre de master en fonctionnement sur le cluster. La base de données répliquées de Kubernetes, etcd, est installée sur les masters. Etcd demande qu'au moins (N/2)+1 masters (division entière avec arrondi inférieur) soient fonctionnels à tout moment.
Si votre cluster possède 3 masters, le nombre minimum de master est de 2 (3/2+1) et vous pouvez donc en éteindre 1.
Si votre cluster possède 5 masters, le nombre minimum de master est de 3 (5/2+1) et vous pouvez donc en éteindre 1 ou 2, tout en restant en fonctionnement normal.
Sortir un master du mode maintenance
L'opération est la même que pour un worker.
Commandes clés
Il y a plusieurs moyens d'adresser le cluster kuberntes. Soit en ligne de commande dont vous trouverez quelques commandes classiques sur cette page, soit via la console kubernetes disponible dans le portail.
Options valables pour toutes les commandes :
- -n : permet de spécifier le namespace sur lequel on veut avoir une action
- -c : permet de spécifier le container du pod sur lequel on veut avoir une action
- -o=name : Affiche seulement le nom de la ressource et rien de plus
- -o=wide : Affiche dans le format texte avec toute information supplémentaire, et pour des pods, le nom du noeud est inclus
- -o=yaml : Affiche un objet de l'API formaté en YAML
Etendre un PVC
Cette procédure permet de modifier la taille d'un PV associé à un pod.
On déroule la procédure avec les PV des pods opensearch du namespace kosmos-search en exemple.
Arreter les pods
kubectl -n shared-search scale sts opensearch-cluster-data --replicas=0
Etendre les PVC/PV à 2,3 To
kubectl -n shared-search patch pvc opensearch-cluster-data-opensearch-cluster-data-0 -p '{"spec":{"resources":{"requests":{"storage":"2357Gi"}}}}'
kubectl -n shared-search patch pvc opensearch-cluster-data-opensearch-cluster-data-1 -p '{"spec":{"resources":{"requests":{"storage":"2357Gi"}}}}'
kubectl -n shared-search patch pvc opensearch-cluster-data-opensearch-cluster-data-2 -p '{"spec":{"resources":{"requests":{"storage":"2357Gi"}}}}'
au bout d'un moment la capacité des PV est mise à jour
kubectl get pv | grep shared-search/opensearch-cluster-data
pvc-1d8679d6-bb17-4789-9e51-7360609feb8b 2357Gi RWO Retain Bound shared-search/opensearch-cluster-data-opensearch-cluster-data-2 lvm-provisioner <unset> 56d
pvc-bc5d66dd-16e8-4297-9c77-de06891c53ab 2357Gi RWO Retain Bound shared-search/opensearch-cluster-data-opensearch-cluster-data-0 lvm-provisioner <unset> 56d
pvc-f166c9de-ab92-40ae-a596-06d1f8b8058d 2357Gi RWO Retain Bound shared-search/opensearch-cluster-data-opensearch-cluster-data-1 lvm-provisioner <unset> 56d
Les PVC refléteront la nouvelle taille une fois les pods relancés.
Relancer les pods
kubectl -n shared-search scale sts opensearch-cluster-data --replicas=3
Consulter la nouvelle taille des PVC
kubectl -n shared-search get pvc | grep opensearch-cluster-data
Constater que le FS dans les containers a été augmenté depuis un shell dans le pod
df -m | grep data
/dev/mapper/kosmosvg0-9bae69f2--a769--45b2--a44c--9a08fd4cd465 2038 60 1979 3% /usr/share/opensearch/data
Ajout d'un noeud Kubernetes
Dans les exemples ci-dessous on considère une plateforme Autonome pour laquelle on ajoute le noeud kubm-k8s00-worker-4.
Adapter cet exemple à votre environnement en mimant la configuration des autres noeuds.
- Vérifier que ce nouveau noeud suit les prérequis de sizing attendus
- Dans
$WORK_DIR/kube-provisioner/os-provided, ajouter le noeud dans l'inventaire de la plateforme (vi ${INVENTORY_FILE}).
workers:
...
hosts:
...
kubm-k8s00-worker-4:
ansible_host: "{{ lookup('community.general.dig', 'compute04.admin.artemis') }}"
node_ip: "{{ lookup('community.general.dig', 'compute04.technique.artemis') }}"
lvm_disk: /dev/sdb
- lancer le playbook en ciblant le nouveau serveur
cd $WORK_DIR/kube-provisioner/os-provided
ansible-playbook -i ${INVENTORY_FILE} kube.yaml --limit kubm-k8s00-worker-4
- Attendre que le nouveau noeud soient Ready et TOUS les pod soient Running ou Completed sur ce noeud
kubectl get node
kubectl get pod -A | grep -Ev "Completed|1/1 *Running|2/2 *Running|3/3 *Running|4/4 *Running"
Suppression complète de Kubernetes
cd $WORK_DIR/kube-provisioner/os-provided
ansible-playbook -i ${INVENTORY_FILE} kube_clean.yaml